publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- NeurIPS WorkshopDeterministic Continuous Replacement: Fast and Stable Module Replacement in Pretrained TransformersR. Bradbury, A. S. Ashok, Sai Ram Kasanagottu, G. Jhingran, and S. MengarXiv preprint arXiv:2511.18670, 2025
Replacing modules in pretrained models—especially swapping quadratic self-attention for efficient attention alternatives—poses a hard optimization problem: cold-start reinitialization destabilizes frozen backbones. We isolate this core stability challenge in a controlled study. Deterministic Continuous Replacement (DCR) blends teacher and student outputs with a deterministic, annealed weight α(t). Theoretically, DCR eliminates gate-induced gradient variance inherent to stochastic replacement (Sec. 3.2). In a single-seed study, DCR attains faster convergence and stronger alignment than stochastic gating and distillation baselines on controlled attention replacement, establishing a foundation for heterogeneous operator swaps.
@article{bradbury2025deterministic, title = {Deterministic Continuous Replacement: Fast and Stable Module Replacement in Pretrained Transformers}, author = {Bradbury, R. and Ashok, A. S. and Kasanagottu, Sai Ram and Jhingran, G. and Meng, S.}, journal = {arXiv preprint arXiv:2511.18670}, year = {2025}, url = {https://arxiv.org/abs/2511.18670}, }
2019
- ICIP
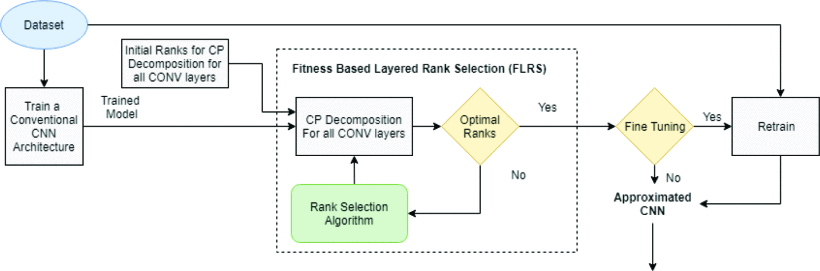 Fitness based layer rank selection algorithm for accelerating CNNs by candecomp/parafac (CP) decompositionsA. Saha, Sai Ram Kasanagottu, J. Mukhopadhyay, P. P. Das, and A. PatraIn 2019 IEEE International Conference on Image Processing (ICIP), 2019
Fitness based layer rank selection algorithm for accelerating CNNs by candecomp/parafac (CP) decompositionsA. Saha, Sai Ram Kasanagottu, J. Mukhopadhyay, P. P. Das, and A. PatraIn 2019 IEEE International Conference on Image Processing (ICIP), 2019We present the Fitness Based Layer Rank Selection (FLRS) Algorithm for Accelerating Convolutional Neural Networks by CANDECOMP/PARAFAC (CP) Decompositions. FLRS selects the layers and corresponding ranks based on a parameter fitness factor. The advantage of the proposed FLRS algorithm is that it does not require retraining iteratively during rank selection. The experimental results show that VGG-16 Network can be replaced by an approximate network where the convolutional layers are replaced by a sequence of four convolutional layers with smaller kernels. The approximated network has less than one-fifth of the original model parameters and performs less than one-fifth of the total number of computations as compared to the original model with an accuracy drop of less than 1% across SVHN, CIFAR-10 and CALTECH-101 datasets.
@inproceedings{saha2019fitness, title = {Fitness based layer rank selection algorithm for accelerating CNNs by candecomp/parafac (CP) decompositions}, author = {Saha, A. and Kasanagottu, Sai Ram and Mukhopadhyay, J. and Das, P. P. and Patra, A.}, booktitle = {2019 IEEE International Conference on Image Processing (ICIP)}, year = {2019}, organization = {IEEE}, doi = {10.1109/ICIP.2019.8803547}, url = {https://ieeexplore.ieee.org/document/8803547}, }
2018
- ICVGIP
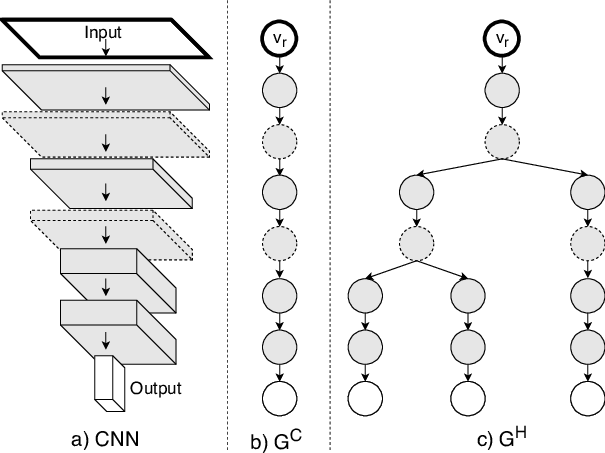 HSD-CNN: Hierarchically self-decomposing CNN architecture using class specific filter sensitivity analysisSai Ram Kasanagottu, J. Mukherjee, A. Patra, and P. P. DasIn 11th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP 2018), 2018
HSD-CNN: Hierarchically self-decomposing CNN architecture using class specific filter sensitivity analysisSai Ram Kasanagottu, J. Mukherjee, A. Patra, and P. P. DasIn 11th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP 2018), 2018Conventional Convolutional neural networks (CNN) are trained on large domain datasets and are hence typically over-represented and inefficient in limited class applications. An efficient way to convert such large many-class pre-trained networks into small few-class networks is through a hierarchical decomposition of its feature maps. To alleviate this issue, we propose an automated framework for such decomposition in Hierarchically Self Decomposing CNN (HSD-CNN), in four steps. HSD-CNN is derived automatically using a class-specific filter sensitivity analysis that quantifies the impact of specific features on a class prediction. The decomposed hierarchical network can be utilized and deployed directly to obtain sub-networks for a subset of classes, and it is shown to perform better without the requirement of retraining these sub-networks. Experimental results show that HSD-CNN generally does not degrade accuracy if the full set of classes are used. Interestingly, when operating on known subsets of classes, HSD-CNN has an improvement in accuracy with a much smaller model size, requiring much fewer operations. HSD-CNN flow is verified on the CIFAR10, CIFAR100 and CALTECH101 data sets. We report accuracies up to 85.6% ( 94.75% ) on scenarios with 13 ( 4 ) classes of CIFAR100, using a pre-trained VGG-16 network on the full data set. In this case, the proposed HSD-CNN requires 3.97× fewer parameters and has 71.22% savings in operations, in comparison to baseline VGG-16 containing features for all 100 classes.
@inproceedings{sairam2018hsd, title = {HSD-CNN: Hierarchically self-decomposing CNN architecture using class specific filter sensitivity analysis}, author = {Kasanagottu, Sai Ram and Mukherjee, J. and Patra, A. and Das, P. P.}, booktitle = {11th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP 2018)}, year = {2018}, organization = {ACM}, doi = {10.1145/3293353.3293383}, url = {https://dl.acm.org/doi/10.1145/3293353.3293383}, } - ICIP
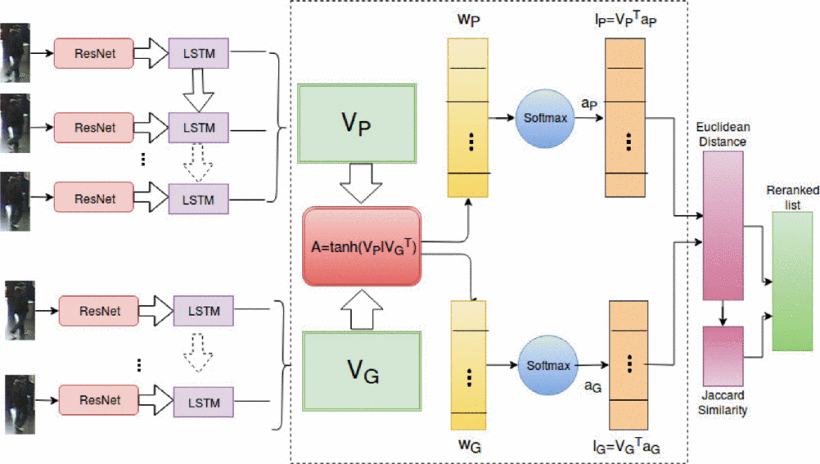 Video based person re-identification by re-ranking attentive temporal information in deep recurrent convolutional networksB. Saha, Sai Ram Kasanagottu, J. Mukhopadhyay, A. Roy, and A. NavelkarIn 2018 25th IEEE International Conference on Image Processing (ICIP), 2018
Video based person re-identification by re-ranking attentive temporal information in deep recurrent convolutional networksB. Saha, Sai Ram Kasanagottu, J. Mukhopadhyay, A. Roy, and A. NavelkarIn 2018 25th IEEE International Conference on Image Processing (ICIP), 2018Person Re-identification (Person re-id) is a crucial task as its application in visual surveillance and human-computer interaction is increasing day-by-day. In this work, we present a deep learning approach for video based person re-id problem. We use residual network (ResNet) along with LSTM for feature extraction. The extracted feature is passed through an attentive temporal pooling layer, which enables the feature extractor to be aware of the current input video sequences. In this way, inter dependency between two images can directly influence the computation of each other’s feature representation. At last, we re-rank the result using k-reciprocal encoding method to mitigate the effect of false matching. Experiments conducted on iLIDS-VID and PRID 2011 datasets confirm that our model outperforms existing state-of-the-art video-based re-id methods.
@inproceedings{saha2018video, title = {Video based person re-identification by re-ranking attentive temporal information in deep recurrent convolutional networks}, author = {Saha, B. and Kasanagottu, Sai Ram and Mukhopadhyay, J. and Roy, A. and Navelkar, A.}, booktitle = {2018 25th IEEE International Conference on Image Processing (ICIP)}, year = {2018}, organization = {IEEE}, doi = {10.1109/ICIP.2018.8451594}, } - ICIP
 Nonseparable filters for images in the block DCT domainJ. Mukhopadhyay and Sai Ram KasanagottuIn 2018 25th IEEE International Conference on Image Processing (ICIP), 2018
Nonseparable filters for images in the block DCT domainJ. Mukhopadhyay and Sai Ram KasanagottuIn 2018 25th IEEE International Conference on Image Processing (ICIP), 2018Filtering of images is required in various applications of image processing. Previously a few algorithms have been reported for filtering of images in the block discrete cosine transform (DCT) domain given its 2D finite impulse response (FIR). However, they assume that the response should be separable along rows and columns. In this paper, we propose a novel technique for implementing a non-separable 2D FIR filter in the block DCT domain. In this approach, we decompose a nonseparable 2D arbitrary FIR into a set of 2D separable arbitrary FIRs, and apply the computation of separable filters in the DCT domain. We have further used the sparsity of the DCT blocks and ranking of separable components in representing the nonseparable filter to reduce the computational cost allowing a graceful degradation of the quality of the filtered output.
@inproceedings{mukhopadhyay2018nonseparable, title = {Nonseparable filters for images in the block DCT domain}, author = {Mukhopadhyay, J. and Kasanagottu, Sai Ram}, booktitle = {2018 25th IEEE International Conference on Image Processing (ICIP)}, year = {2018}, organization = {IEEE}, doi = {10.1109/ICIP.2018.8451369}, }